


Did you ever wonder if there is one single idea out there, that could make you a better software developer, significantly, if you understood it?
There are no shortcuts to being a better developer, but there are concepts that can help you improve your coding style once you start thinking about them.
In this article, I will attempt to approach the idea of setting boundaries in what your code can and cannot do. I will try to prove that sometimes, it is better, to think inside the box.
Boundaries are everywhere
Everything around us has boundaries. For example, in the physical world, everything occupies a certain amount of space. The laptop I am typing this article on has a "start and an end" when it is perceived as a physical object. Boundaries that are so obvious as the space occupied by a laptop are easy to identify. Everyone uses them as "tools" without even thinking about them. I can reach and pick up the laptop because I can see where it is.
Moving away from the material world, a more abstract example of boundaries can be the borders of a country. Although a physical boundary (e.g river, mountain) can form the border of a country, in most cases the borders are "political boundaries" that are drawn to a map, so we can tell, where a country "starts and ends". They are boundaries that we all agree to exist, so they exist.
Boundaries in software
Approaching closer to the idea of this article, an even more abstract example of boundaries can be found in software development. In many aspects of an application, the idea of boundaries is at least a perfect tool to explain and communicate some complicated information. For instance, the human brain cannot conceive the full image of a system's architecture if it is not broken down into pieces. Pieces that are usually represented as boxes in our diagrams describe different parts of the system. These pieces have a start and an end, too. And the importance of that is of great value.
Even more, this mental image of boxes (that are boundaries set around different parts of the system) helps you concentrate and think about what one of these boxes should do. Phrased differently, you are forced to think what is the problem that a part of the system is responsible to solve.
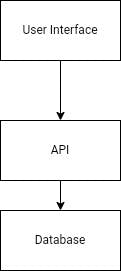
In the above, simple diagram, we see the 3 main components of a system represented as boxes. By looking at it we know 3 different areas are responsible for different jobs. They interact with each other but they don't mingle in any case. Perceiving our architecture as separate boxes helps us understand and build our system.
Boundaries exist organically in our systems and they happen to be the ideal tools to understand and explain complex ideas. We isolate functionalities and responsibilities in a way that the human brain can comprehend them and then work on them. Even though we encounter architecture diagrams more often, boundaries exist also in the code of our systems.
What are boundaries in code?
Abstract concepts like "boundaries in the code" are hard to explain to someone that has never encountered them being applied in the real world. Thankfully though, boundaries are everywhere in the code, and we use them every time we make even the smallest change. We just need to shift our perspective to see them.
To be more specific, every class, function and any kind of scope created by opening and closing brackets are forms of boundaries. They have a start and an end. Thinking in a bigger scope, modules implemented under a certain namespace are another form of “borders" in our code.
If we agree that boundaries appear everywhere in the code, it is obvious then, that if we learn how to use them they can be proved to be of great value. Organizing the code so every part of it is focused on a specific problem is a great start. We don't want big functions that hold a lot of functionality because they are hard to understand and change.
Setting hard boundaries on what a function can and should do is a very important idea that changed my approach to coding. As with software architecture, in code, boundaries help us understand and break down our code into clearly defined boxes.
The idea of boundaries, as used in this article, is deeply interlinked with ideas/concepts that are widely accepted as good practices for writing better software. You can find multiple resources from the great minds of programming for subjects such as “Separation of concerns”, “Single Responsibility”, "Modularity", "Don't repeat yourself" and "Decoupling". In my article, I just attempt to introduce the same ideas expanding from one common anchor point: the boundaries in our code.
Setting example code
// before I started thinking about boundaries
function manipulateAndSave($data) {
$data['manipulated'] = true;
$q = buildQuery("INSERT INTO users (data)
VALUES ($data)");
$q->run();
}
// after I started thinking about boundaries
function manipulateData($data) {
$data['manipulated'] = true;
return $data;
}
function insertIntoTable($data) {
$q = buildQuery("INSERT INTO users (data)
VALUES ($data)");
$q->run();
}
Thinking inside the box
A function (or class) has a specified reason to exist, that is its boundary. The function has to be created with this boundary in mind and deliver only a specific functionality. Limiting the scope of responsibilities for each area of the code is the result of thinking in boundaries. The single responsibility (from S.O.L.I.D principles) principle is all about that boundary.
In addition, a function that does a specific job is easy to maintain as it is easy to "load" in your brain and analyze it, but also it is not susceptible to many changes. If a function exists only to do x with x being a very specific and isolated task (Separation of Concerns), then the function will need to be modified only and only if x needs to change!
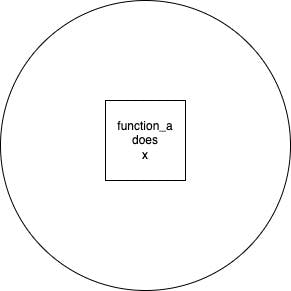
Think inside the box when you code. A box can be the function you are working on and what it is responsible for.
Don't Repeat Yourself
Striving to create well-focused functions, that do x (some functionality confined inside proper boundaries), will make them suitable to be used again in different parts of the code when x is needed.
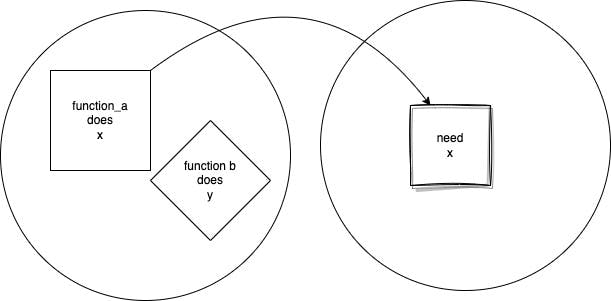
On the other hand, imagine a function that does x and y (y being another piece of functionality) at the same time, then it would be impossible to reuse it where x or y were needed. You have coupled together x and y so none is reusable. DRY (don't repeat yourself) is one more widely accepted principle of better coding standards that we should strive to achieve where possible. Good boundary setting helps a lot to stop repeating ourselves when we write code.
Forced to be modular
If we think in terms of boundaries, of what our code can do, we are forced to create modular code. That means our code is structured in a way that parts of it can be removed so different, suited implementations can replace them. If the parts are well-thought they can be used to "compose" the functionality we want by arranging them as needed.

Photo by Tara Winstead: pexels.com/photo/wooden-shapes-toy-6692946
If we have a function that retrieves the data of a record from the DB, manipulates these data, and then saves them in the DB, it does too much (before refactoring). If we need to replace the existing DB technology with a different type of DB, for example, if we want to change from an SQL to a Document storage, that function will need to be altered.
In addition, if we need to change the logic that manipulates that data the same function is again to be altered, and possibly affect how we save data in the DB. These extended boundaries, of this function, contain both manipulation and persistence code making one coupled with the other. Any change to one of them is possible to break the other one.
Alternatively, if we split the logic into two separate functions (after refactoring) (Separation of concerns), it would be much easier and safer to remove the function that retrieves the data from the SQL storage with one that retrieves the data from the Document storage. This change would still require the part of data retrieval to be rewritten, but it would be confined to the boundaries of the corresponding function. The rest of the code will be unaware of the difference that was made.
One more benefit of modularity is that the interfaces between modules become part of our design, forcing us to consider how different parts of the system will interact with our code. This is one more game-changing idea for me, as most of the systems I have worked on don't respect the boundaries so much resulting in blobs of data being passed around crossing all kinds of boundaries (leaky abstraction) and causing unpredicted behavior and uncertainty in the code.
Easy to move toward the unknown
Designing your code in small isolated parts that deliver specific functionality, enables you to start coding them before you have all your solution figured out. This improvement makes you much more agile in tackling software engineering in general. You build what you know, test it, and deliver it without caring about other dependencies. Blockers can be eliminated by replacing unknown parts with “dummy” implementations that will be replaced later when the knowledge needed is gathered.
Going back to the example of the two functions above, there are multiple scenarios in which you could be blocked if you wanted to deliver the whole big function at once. Imagine if you did not know yet what type of storage you would use (this can even be a decision of another team), would you cross your arms and wait for that decision to be made or start working on what you know? I vote for the latter, you can define your function’s boundaries as the “function that holds the manipulation logic” and implement it. You can even go one step further and create a dummy function that “fake” saves data in a DB so you can define the communication between these two functions too!
The ability to start writing code before you find out all the unknown is crucial, enabling the developers to experiment and get feedback, on their code, as early as they can.
Staying focused on one thing at a time
Thinking “in" boundaries will increase your focus and guide it on the individual task. Knowing that the function you are creating is responsible for solving one and only one problem will force all your attention to be directed toward that one problem.
In the past years, the idea above was one of the biggest differences I have seen between experienced developers and the rest of us. It was eye-opening to watch and compare the commits from different developers. The more "junior" commits would have code changes scattered in different functions and classes, whilst the senior commits were small functions that delivered small pieces of functionality.
It is liberating to be able to focus on one part of the code without thinking about all the rest but it is important to always think about how this part will interact with everything else.
Boundaries create testable code
One popular and widely used type of testing is Unit testing. With unit tests, we aim to test a “unit” of our code, which can be a class or a function. If our functions are defined by well-thought boundaries then they are easy to test, because specific functionalities are isolated and can be tested in a vacuum.
On the other hand, highly coupled code is hard to break down into smaller pieces and test if they work as expected. Simply put, a function that is doing too much, cannot be broken down into individual pieces that are testable.
In our example function, before the refactoring, the function was the manipulation of the data and was also responsible for saving them in the DB. If we wanted to test the manipulation logic was impossible without testing the persistence logic too. The test will not return specific feedback for a “unit” of our code, rather it will return feedback for “all” the process, leaving us not knowing what went wrong.
After refactoring, the code that manipulates the data is separated and easy to be tested alone. We can check if the manipulation algorithm does what is expected and get feedback only for it. In addition, the persistence logic can now be tested and validated as a different unit of our code.
Conclusion
Having well-defined boundaries in your code can help you write better software. As with everything in our profession, it will require practice to start getting the benefits of that idea.
This article is just an attempt to scratch the surface of bigger concepts from a unified perspective. But hopefully, it will show you that this idea is worth your attention. Check more resources that are related to the concepts mentioned above to have a deeper understanding of what boundaries are all about.
And never stop learning!
cover photo by Alexey Demidov: https://www.pexels.com/photo/red-and-white-stop-sign-10058530/